Over the past few months, we have been investigating the opportunities for a possible Jisc-delivered text and data mining (TDM) service and analysing options for how we might do so, initially across two existing Jisc services: CORE and Journals Archive. These two platforms already deliver significant amounts of digital content, in the form of scholarly articles, and their combined corpus could immediately facilitate new research opportunities and lines of enquiry if text mining techniques were applied to it.
Currently referred to as the Jisc Gateway to Text and Data Mining (or JGTDM), the scoping phase of a potential service has completed, so now seems like a good point to take stock and to communicate about what we have been doing.
Why are we interested in this?
TDM is the effective leveraging of computational research methods, either to generate new forms of research outcomes, or to deliver traditional outcomes more efficiently and with a higher level of accuracy. As more machine-readable content has become available, many scholarly disciplines have steadily grown their level of engagement with TDM and it has moved closer towards the mainstream. From entity recognition, through sentiment analysis corpus linguistics, there is a wide range of TDM manifestations, used to differing ends by just as many disciplines.
Nonetheless, the barriers to entry are not insignificant, often requiring researchers to acquire additional, technical skills or to partner with collaborators who can deliver the specific forms of assistance. And, while TDM offers an opportunity to improve the way we access and analyse research literature, creating the infrastructure enabling algorithms to process research literature at scale is a significant organisational and technical challenge.
This is why we believe Jisc may be able to help on a sector-wide basis.
In late 2017, Jisc commissioned an investigation, from consulting group Tessella, into the demand for TDM within the research community and the opportunities for Jisc to engage with this field. This work was subsequently extended by Petr Knoth of the Open University to:
- Produce a technical assessment and architecture model for developing a prototype JGTDM service
- Identify a set of prototype options for the development of the service and assess them in terms of their feasibility.
In Tessella’s initial survey (of 123 people) 87% of respondents declared a positive response (‘somewhat’ or ‘very’) to the idea of a Jisc service to support TDM, 68% felt it was something that they needed and 84% believed themselves likely (‘somewhat’, ‘very’ or ‘extremely’) to make use of it. Even though the survey group inclined somewhat towards respondents with some experience of TDM, it still indicates a clear opportunity to develop an offering in this field.
The way ahead
The goal of Jisc Gateway to Text and Data Mining is to provide a solution which supports both experienced and novice practitioners of TDM – a service that is intuitive and easy to understand, yet with capabilities sufficient to be of real value to the majority of users.
Whilst still in its formative stages, a broad approach has been identified, which seeks to combine three key elements:
- A mechanism allowing users to define and create their own, task-specific corpora from a ‘pool’ dataset created from CORE and Journal Archives.
- A workflow environment in which corpora can be interrogated and processed using TDM components from an available toolkit. To begin with, this range of tools will be limited and will concentrate on providing those most widely-used.
- Training materials and helpdesk assistance, as well as mechanisms to share experiences and best practices, in order to encourage and support a community of practitioners.
How to achieve this?
Following on from the evaluation of various options for creating and delivering this service, the approach selected for the prototype is one of ‘federated, lazy-evaluation content delivery’, whereby federated searching of CORE and Journal Archives will be used to draw content into a user-defined corpus, cached temporarily in JGTDM, across which workflow processes are then conducted.
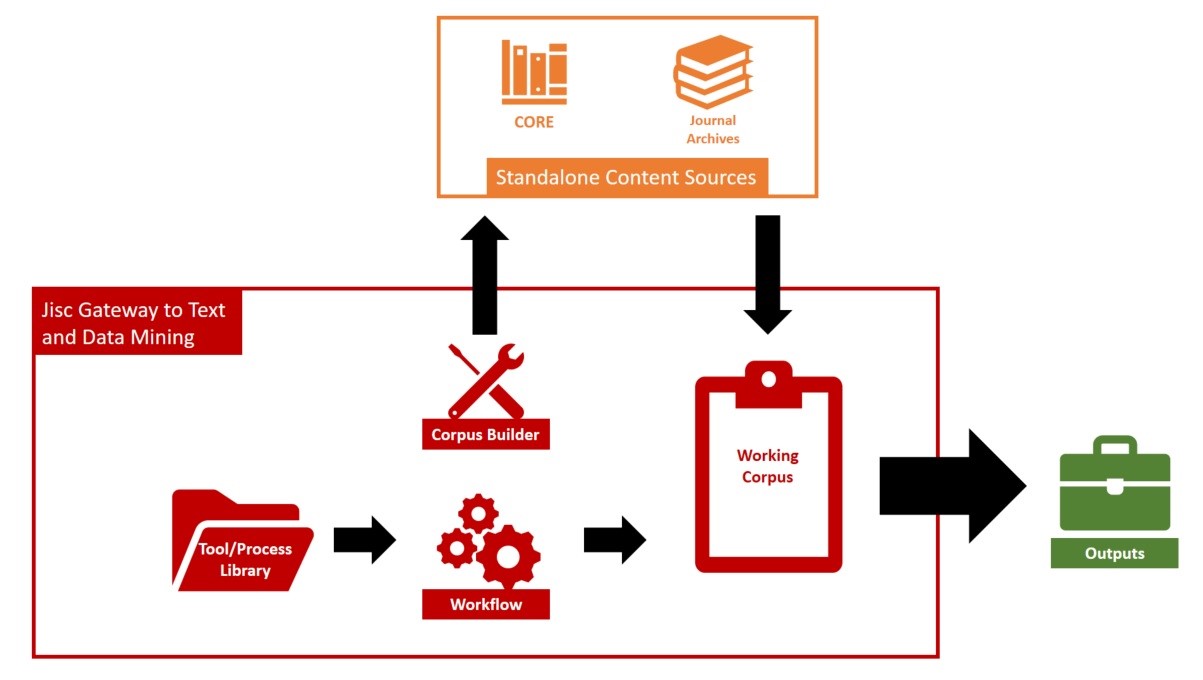
One objective of the prototype will be the evaluation of this approach as a mechanism for future use, should the service’s development progress and its scope extend.
What’s Next
We are currently assembling a detailed project plan for the JGTDM prototype – mapping workstreams to tackle a number of distinct areas, such as evaluating and detailing the technical solutions proposed above, prioritising the TDM tools that need to be included in the initial deployment of this service – such that it is adequate to the task of measuring interest and user response – and exploring issues of sustainability and the potential place of such a service within the wider landscape of TDM activities.
We’re looking forward to keeping you updated as this exciting project progresses over the coming months, but if you have any queries in the meantime, please don’t hesitate to contact:
Stephen Brooks (stephen.brooks@jisc.ac.uk) or
Sarah Fahmy (sarah.fahmy@jisc.ac.uk)