This is a guest blog post written by Dr Fiona Murphy, MMC Consulting, https://orcid.org/0000-0003-1693-1240 and Dr Phill Jones, Double L Digital Consulting https://orcid.org/0000-0003-0525-6323.
Reference back to these posts about the wider project: https://orcid.org/blog/2020/08/03/orcid-and-uk-national-pid-consortium

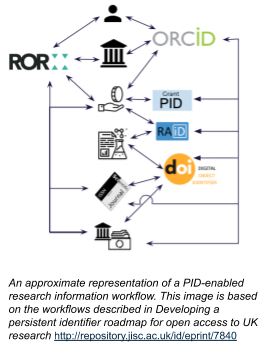
Our third post in this series reports on the key findings of the recent focus group on organisation IDs, and how these could be integrated into the research ecosystem more effectively as part of the broader Jisc PID strategy project.
The group consisted of representatives from infrastructure organisations, libraries, and UKRI.
Context
Research organisations have an obvious and critical role in the research infrastructure, as both trainers and employers of researchers, as well as being the administrative and physical home for many research projects. On an individual level, researchers’ home institutions have long signified prestige and reputation. In recent times, the growing importance of strategic research management on an institutional, national, and regional level, together with the drive towards open research, have brought into focus the need for a unique persistent identifier (PID) for institutions.
Currently, there is no universally adopted, open PID for organisations — despite the fact that the need for one has been well understood for several years.
GRID and Ringgold’s proprietary identifiers are variously used as identifiers in the research/publishing space. However, both are controlled by individual commercial organisations, which some in the scholarly infrastructure space see as posing a systemic risk, as well as being broadly incompatible with the idea of open infrastructures for open research.
The two community-led identifier initiatives for research organisations — the International Standard Name Identifier (ISNI), and the Research Organisation Registry (ROR) — both have the potential to evolve into a standard PID equivalent to DOIs for outputs and ORCID iDs for people.
ROR
ROR was launched in January 2019 as a community-led project with the support of Crossref, DataCite, and California Digital Library. It’s based on the GRID dataset, which was donated by Digital Science. The initiative is focused on “proper description of relationships between contributors, contributions, research sponsors, publishers, and employers” (1) and has an open Application Programming Interface (API) for access to data.
ROR does not yet have a business model, but it is well funded via grants for the medium term. It maps to other organisation IDs, and all data is fully open. Since the organisation is still fairly new, it’s still gaining traction, but the open API is enabling a range of organisations to adopt it with minimal friction. The list of integrations on the ROR website includes EuropePMC, Crossref, DataCite, and ORCID.
ISNI
ISNI emerged from the library community in 2012 and consists of a global database of named entities — organisations as well as people, companies, and fictional characters. Much of its usage comes from rights management and the content industry. ISNI also has an API, which is a critical component for integrations with other systems, but it is less well developed for scholarly infrastructure use cases and less scalable.
ISNI itself has no dedicated technical resource to build or maintain services. Coupled with ISNI’s fairly broad remit, which requires the support of many use cases beyond those relevant to scholarly infrastructure, progress and changes to ISNI systems have therefore historically been very slow.
ROR vs ISNI
During the Organisations focus group session, there was a rigorous discussion of the relative merits of ROR and ISNI. While ISNI is well-established and has wide coverage, the group felt that there is a governance concern or gap, and a lack of consolidated community involvement.
ROR was noted to have the inverse set of challenges. It has community support, governance, and momentum, as well as being open source with an open API. On the negative side, ROR is not as granular as ISNI and does not currently include internal department level information.*.
Overall, the sense that ROR is heading in the right direction was seen as the most important consideration among the group. Critically, the participants felt that ROR’s governance model had greater flexibility and was more likely to be able to respond to emerging needs in the scholarly infrastructure ecosystem.
Governance and sustainability
The focus group discussed questions around governance and sustainability of the PID consortium in general, as well as PID solutions for organisations in particular.
There was overall agreement that organisational IDs need to be adopted throughout the lifecycle of research. Only then can the value be maximised. There is an inherent collective action problem here in that, unless a critical mass of institutions, funders, and product vendors all adopt the same identifier, the value of adopting any identifier will be greatly reduced. The group suggested that Jisc, UKRI, and other national-level organisations could show leadership here. A strong signal of national-level adoption in the UK could be the spur that institutions, publishers, and funders need to get on board with using ROR.
Moving forward
The group recommended an exploration of the points of intersection between an organisation ID and other persistent identifiers, prioritising the interventions that add the most valuable functionality to the whole system, and exposing easier wins through improving user experiences such as workflows. ROR emerged as the best option for this, as it has appropriate technical interfaces, community engagement, and a governance structure that will allow it to develop to meet community needs.
1. https://ror.org/scope/
* The original blog post has been corrected as it incorrectly stated that ROR ‘does not cover private organisations’. In fact, ROR includes a number of organisations that could be classified as private, from major companies (such as Apple (https://ror.org/search?query=apple) and Pfizer (https://ror.org/search?page=1&query=pfizer)) to small research centres or non-profits (for example, Hummingbird Monitoring Network https://ror.org/03kdbx663).