This is a guest blog post written by Dr Fiona Murphy, MMC Consulting, https://orcid.org/0000-0003-1693-1240 and Dr Phill Jones, Double L Digital Consulting https://orcid.org/0000-0003-0525-6323.
Reference back to these posts about the wider project:
https://orcid.org/blog/2020/08/03/orcid-and-uk-national-pid-consortium

In this last in our series of blog posts from the recent Jisc persistent identifier (PID) focus group meetings, we explore how IDs for research outputs could be integrated into the research ecosystem more effectively via the Jisc PID strategy. (Note that we use ‘ outputs’ throughout as it’s a broader and more inclusive term than ‘publications’.)
This focus group consisted of representatives from funders, infrastructure providers, publishers, and institutions.
Context
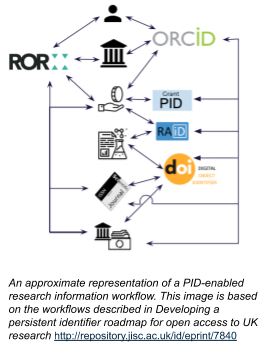
Research outputs are a critical element of any persistent identifier strategy. Although Handles, ARKs and ISBNs were discussed in the course of the session, the group agreed that Digital Object Identifiers (DOIs) from Crossref and Datacite represent the most fruitful line of enquiry, because:
- The Plan S principles call for the use of PIDs for scholarly publications, with a preference for DOIs
- Plan S also calls for the use of PIDs for ‘relevant entities’ and links to ‘data, code, and other research outputs that underlie the publication’
- The Freya project concluded that DOIs are the most used PID for articles, and DOIs, followed by Handles, are the most used for data
- Datacite and Crossref DOIs have metadata linking them to services that are relevant to scholarly infrastructure, for example, ORCID
However, while Crossref, Datacite and the DOI standard are well-established for more traditional outputs, such as articles, book chapters and datasets, other areas are still in development. For example, some content types like preprints and peer review are still relatively young. This shaped the focus group discussions to focus less on, ‘what are output IDs and how should we use them?’; and more on, ‘how do we extend the range of outputs for which PIDs are applied, and which organisations, entities, and domains are missing from this dialogue?’
Consequently, the Outputs focus group started by discussing the potential tension between optimising workflows for the types of outputs that are most strongly incentivised today – articles – and influencing the way that assessment could be carried out to be more inclusive of other outputs, for example, based on the Knowledge Exchange Openness Profile project or open data metrics.
Challenges around technical expertise and resources for both smaller institutions and smaller publishers were raised as barriers to adoption and best practice. This led to a general agreement that the creation of a consortium, like the UK ORCID consortium or the British Library DataCite consortium, would potentially be an effective way to spread the cost, and the administrative and policy burdens.
Appropriate breadth of output types
The focus group had an interesting discussion around the breadth of types of outputs that should be identified and recognised. One participant suggested that the PID project itself was too focused on research articles and, to a lesser extent, books. Practice-based research, in particular, was seen as underrepresented both in the existing infrastructure and the proposed interventions.
A broad range of output types was suggested, including:
Visual art, Performances, Datasets, Software, Designs, Policy and advocacy, Workflows, Outreach activities, Buildings/centres, Film, Sound, Speeches, Performances/plays, exhibitions, Conferences, and Collections.
For reference, the current list of DataCite objects is:
Audiovisual, Collection, DataPaper, Dataset, Event, Image, Model, InteractiveResource, PhysicalObject, Service, Software, Sound, Text, Workflow
The Crossref list is:
Book section, Monograph, Report, Peer review, Book track, Journal article, Part, Other, Book, Journal volume, Book set, Reference entry, Proceedings article, Journal, Component, Book chapter, Proceedings series, Report series, Proceedings, Standard, Reference book, Posted content, Journal issue, Dissertation, Dataset, Book series, Edited book, Standard series
It’s worth bearing in mind that the specific metadata associated with an output type is what establishes the output type, not the agency it’s registered with or the type of identifier used. In other words, Crossref holds datasets (see above) from the period before DataCite was launched. However, current practice is for Crossref to refer requests for registering datasets directly to DataCite. as they provide services that better support this content type. This results in a better service for users, and strengthens the case for the agencies themselves to have a joined-up approach to the scholarly ecosystem.
The group’s suggestions for output types that need to be covered maps well to those already supported by DataCite. Several participants suggested output types that are really collections of one form or another. A project ID like the RAiD could be thought of as a collection of objects that may or may not include one or more articles, art pieces, grants, people, organisations, and so on. Care must therefore be taken that the right sort of PID is used for new types of objects.
It’s also worth noting that grants, data management plans, and even articles themselves can also be thought of as collections. This problem of hierarchy can be resolved by thinking of all of these classes of objects existing as equal nodes in a PID graph.
Adoption issues
Some participants were surprised to hear that many repositories don’t follow best practices around Handles and DOIs. For example, some repositories don’t expose their Handles, or don’t maintain them persistently when migrating content. This prompted a lively discussion on how to remedy the situation. On a technical level, something similar to the DNS network that self-propagates was proposed. On a cultural level, participants felt that getting repositories to report their level of DOI adoption and create a sense of virtue around good PID practice may help.
Challenges for small organisations around lack of resource and technical expertise hinders the meaningful adoption of PIDs. The cost of registering and maintaining metadata — including the PIDs themselves — can be a particular burden, both for institutions and publishers. For example, the need for publishers to update DOIs with new URLs creates a point of failure, particularly when journals change hands.
Governance
Participants noted that other organisations have already put work into governance. This should therefore be studied, and anything already successfully established should be used. One participant felt that DSpace was quite far along and doing well in terms of governance for output-related projects.
The need for community governance and openness was highlighted as a way to develop resilience, establish mechanisms for addressing the issues outlined above, and prevent dependence on any one organisation. Again, the national consortium route has the potential to engage with international and global initiatives, enabling UK-based research and researchers to remain active and relevant to their disciplinary peers.